

Solutions
Industries
© Copyright 2026. All Rights Reserved.

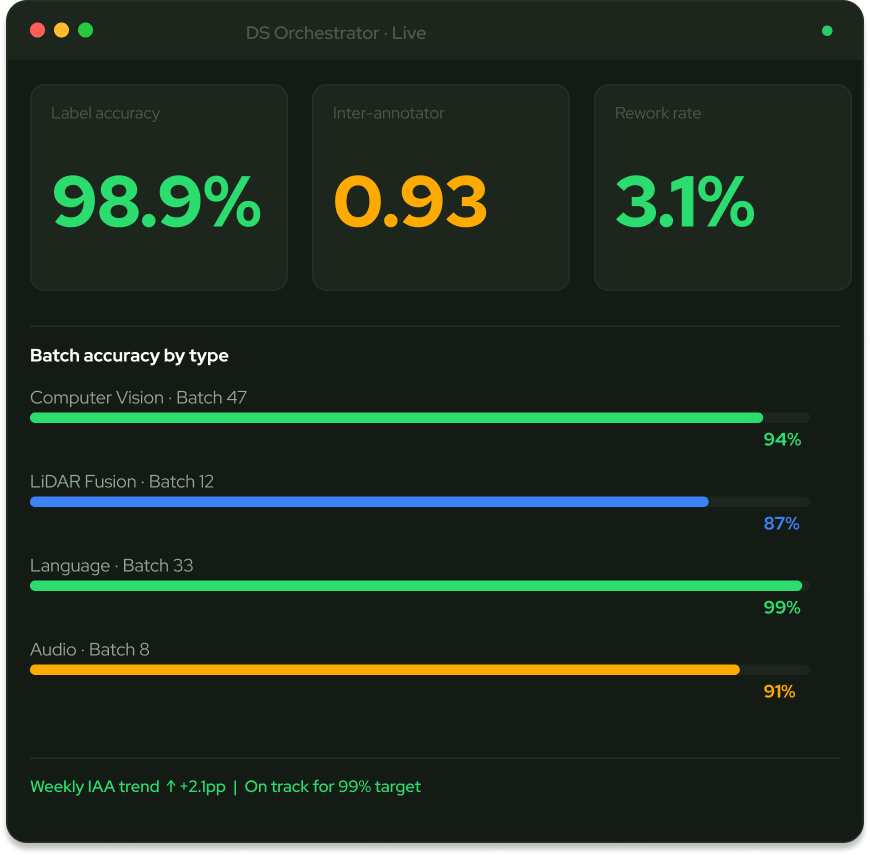
Annotation quality that holds at sample scale collapses in production. The hard part is keeping a distributed reviewer pool consistent against an evolving rubric — and proving the dataset is sound.
Inter-annotator agreement drifts as guidelines evolve and reviewers rotate, quietly degrading model performance.
Work spread across Labelbox, CVAT, internal teams and contractors, with no shared QA or source of truth.
When a model misbehaves, you cannot trace it back to the labeling decisions behind it.
Bounding boxes, segmentation, keypoints and classification to pixel-level accuracy.
LiDAR, radar and camera-fusion labeling with multi-sensor QA for perception teams.
NER, intent, transcription and linguistic annotation with inter-annotator calibration.
We codify, version and re-calibrate guidelines as your taxonomy evolves.
Automated checks, peer review, expert adjudication and DS spot-audits.
Your platform, our reviewers and QA, delivered straight into your pipeline.
Targets we govern to and report on every program; engagement results are shared under NDA.
DS Orchestrator tracks the signals that keep a dataset production-grade, with full provenance per batch.

Labelbox
CVAT

V7 Darwin

SuperAnnotate

Label Studio

Roboflow

Scale AI

Encord
— and any annotation platform via API —
Bring one dataset where accuracy or consistency is slipping. We will calibrate it, run it through DS Orchestrator, and hand back a per-class quality report.
